

How to Choose a Data Protection Type: Datasets & Encryption
This document offers an overview of popular data protection techniques, including those provided by Ubiq, and provides guidance on choosing the most suitable option for your use-case. Because it was written by our technical team (and not marketing - no offense), it doesn’t just focus on techniques that Ubiq can provide. Although we believe encryption is the optimal method (and created a product to do that), this paper is intended to persuade you of its merits without misleading you into thinking it is the only choice available.
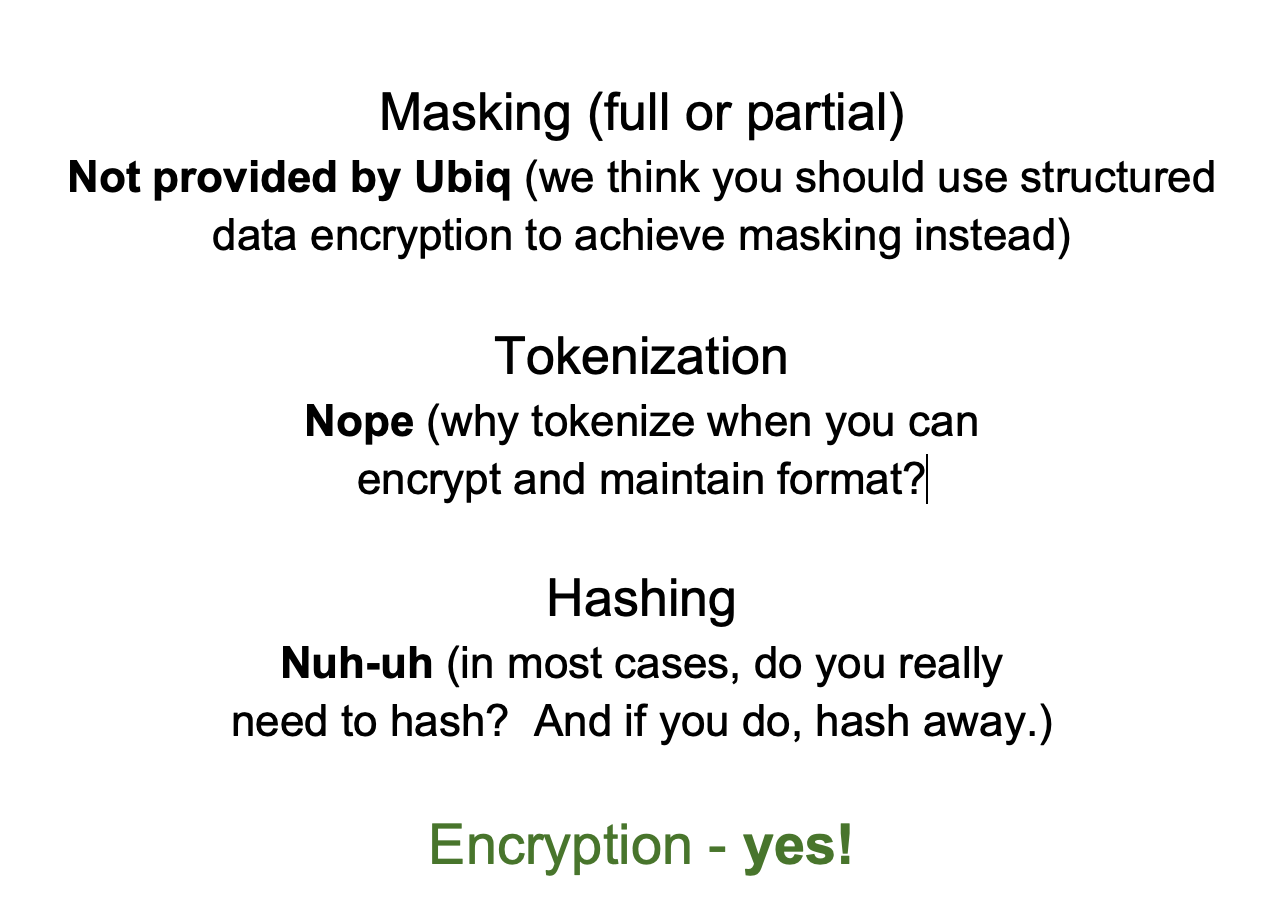
To wrap up the disclaimer, we’ll be covering the data protection techniques below. Read more to understand why we think encryption is the best option in most cases:
Data Protection as a practice is wide and covers a ton of different techniques, from physical security to staff access policies. This discussion aims to focus on a more narrow piece of data protection, specifically techniques that operate on the data to render it less sensitive and more secure. Industry products and pundits have created their own vernacular around this space, with little consistency and fewer rules about what their terms mean. Things like “encryption,” “masking,” and “tokenization” are often used in the same sentence, or worse, used interchangeably or without regard to the business or security goal they are being applied to.
At Ubiq, we’re big on transparency (not the encryption type, the way-of-life type.) So to start with, let’s distill some of these terms down to definitions that we hope most of us can agree on:
Data Masking
Data masking we’ll define as a technique to change the characters in a piece of data so that it is no longer sensitive, but is recognizable in structure.
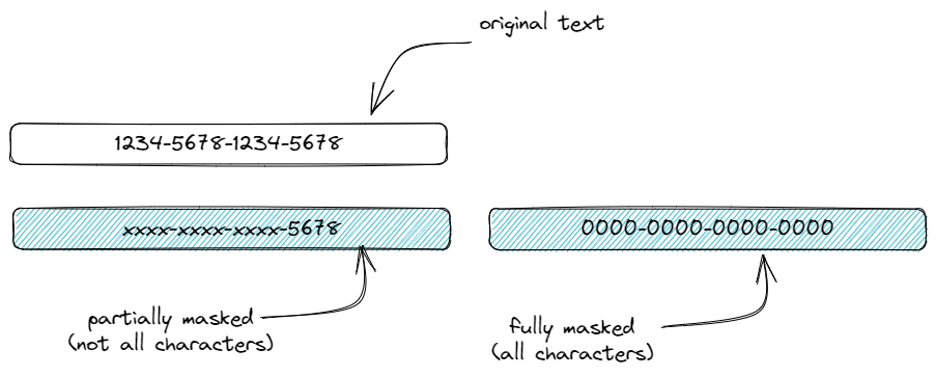
Data masking can be full, where all of the characters are changed (like when you type a password into a form on a website and it is replaced by dots), or it can be partial where only a subset of characters are changed (like when you see your bank account number on a statement and it only shows the last 4 digits).
For the sake of our definition, we’ll say that the character(s) used for the “masked” part are arbitrary - they are commonly the same (like an “x” or a dot or a zero), but that doesn’t matter. We’ll also follow the common assumption that data masking is non-reversible, meaning that the original text cannot be retrieved from the masked text.
A Note on Masking Irreversibility: not everyone in the security industry means “irreversible” when they say “masking,” but it’s much more common for masking to be a permanent replacement (irreversible), so for simplicity-sake, that’s what we’ll stick with for our definition.
The advantage of masking is that it can be used “in-place,” meaning that the masked data structurally looks and feels like the original data, so an application or a human that’s seeing it doesn’t need to change when data goes from plaintext to masked text. This is advantageous when that data is stored in a database (with length or character restrictions), used for other logic in business processing, or needs to be readable.
Tokenization
Data tokenization is sending the sensitive data to a secure location, exchanging it for a non-sensitive “token” that can later be exchanged again or used to reference the original data.
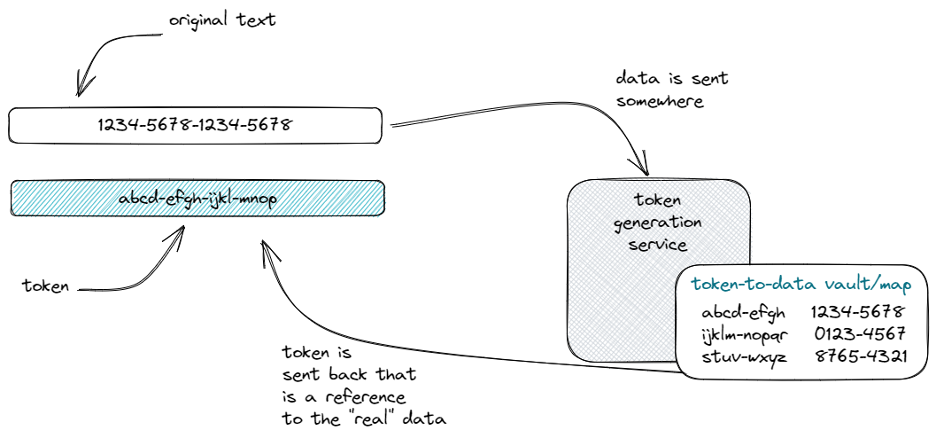
Tokenization has the important characteristic that the real data still exists somewhere and that the token references that data like the primary key of a database table references its row. In practice, the “real” data is stored in a system different from where the token is stored (it would defeat the purpose of tokenization otherwise…) but we won’t dictate that in our definition. The important point is that the token is a pointer to the real data, but they are stored separately (and duplicatively.)
The structure of the token isn’t something we feel needs to be defined - it can be anything from a random string to a hash.
Tokenization became popular as a PCI-DSS regulatory solution to allow credit card processing without storing credit card data. Instead, merchants store the token that they can later use to interact with the credit card processor, who can look up the real credit card info from that token. How secure the actual credit card data is stored isn’t the concern of tokenization (ironically?), and in our opinion, tokenization is a legacy technique that does not have many practical use-cases for data protection.
Hashing
Hashing is likely the most well-understood and well-defined technique that we’ll list here. Because of that, our definition will get a bit nerdy, so the easy part first: hashing is a cryptographic process that turns text into an irreversible, deterministic, and fixed-length set of characters.
Irreversible - that the original text cannot be retrieved from the hash (one-way math.)
Deterministic - that applying the same hash algorithm to the same text will always result in the same output
Fixed-length - that a hashing algorithm will always produce text of the same length (i.e. SHA-1 hashes are always 160 bits)
Some other more nuanced characteristics of hashing that we’ll add to our definition include:
- That input text likeness is not correlated to hash likeness (i.e. a hash that is similar to another hash doesn’t mean that the input content was similar)
- Hashing is collision-resistant; note that this is not collision-proof … collisions of hashes ARE possible, but mathematically unlikely
Hashing is a common technique used for comparing that two pieces of data match, such as checking that the password you typed in matches the one stored (as a hash) somewhere by hashing the test input and comparing the two hash results. It allows for equality-checking without having access to the original text. Hashing is also widely used in software development as an efficient way to reference or look up data - a la “hash tables.”
Unfortunately, hashing has the limitation of being collision-susceptible, which adds complexity in large datasets. While hash functions themselves are not mathematically unbreakable, a good cryptographic hash function should satisfy certain properties that make them resistant to various attacks. These properties include pre-image resistance, second pre-image resistance, and collision resistance. In theory, a cryptographic hash function can be considered "broken" if an attacker can find collisions or reverse the hash function with significantly less computational effort than a brute-force attack. However, many widely-used hash functions, such as SHA-256 (Secure Hash Algorithm 256-bit), have undergone extensive analysis and are considered secure for most practical applications.
Encryption
Encryption itself is a generic term, and since it’s our focus here at Ubiq, we’ll spend a little time unpacking what we believe “encryption” means.
The internet says that encryption works “by scrambling data into a secret code that can only be unlocked with a unique digital key” (https://cloud.google.com/learn/what-is-encryption) but that seems a little too 3rd grade to us. Mind you, it's true - and early forms of encryption date back to Caesar, but we think when we’re talking about encryption we should define it in a way that’s most applicable to modern encryption. So to that end, if we’re stuck with just the word “encryption,” we define it as a mathematical/cryptographic process that applies a “key” to a sensitive text to change the characters in a way that is reversible.
There are many different types of encryption, from the cracker-jack-box decoder ring that turns “A” into 1, “B” into 2, etc. to common algorithms like AES-256 and uncommon algorithms that maintain form and character preservation.
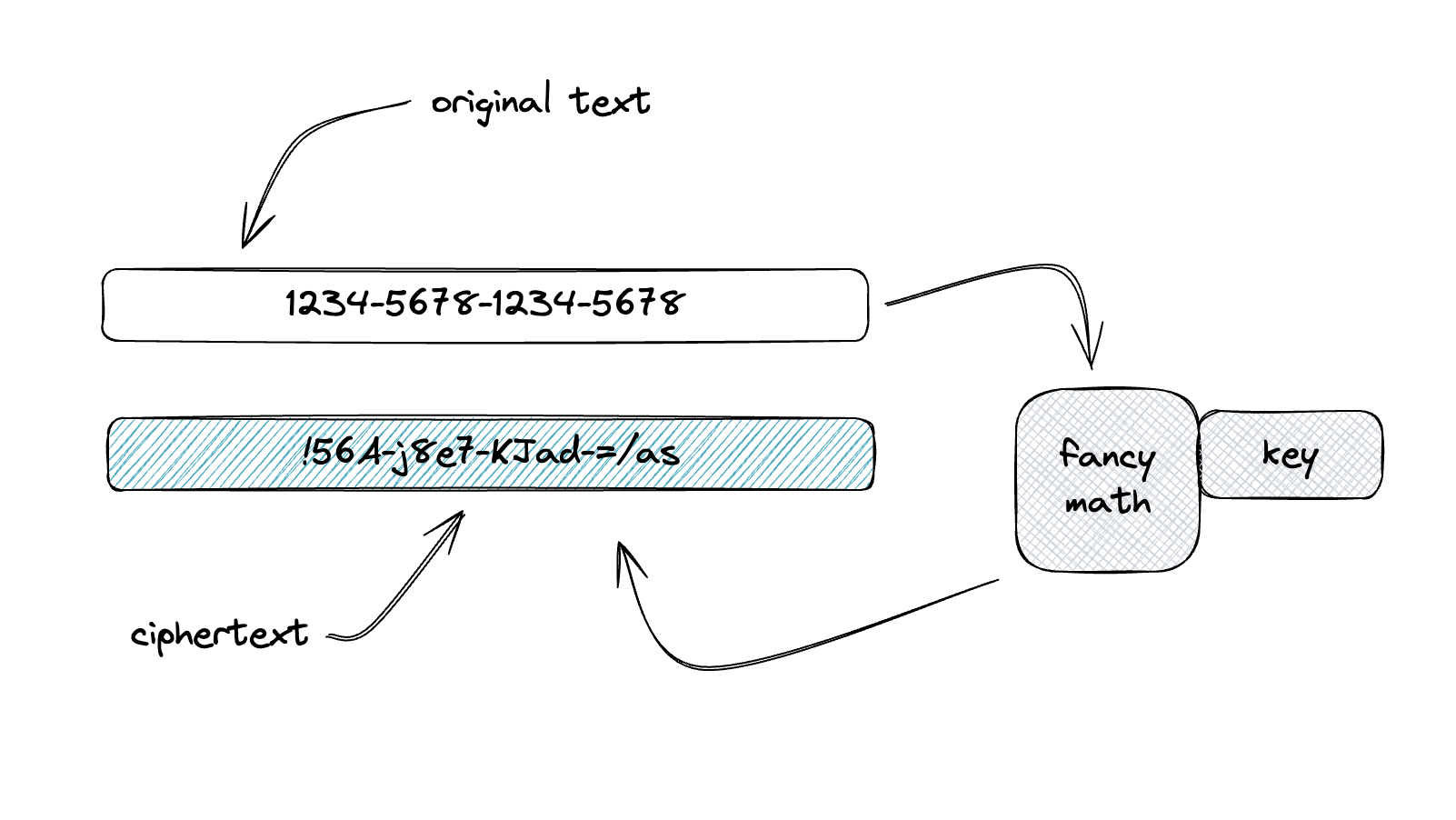
We (obviously) have a lot to say about encryption, so we’ll get into its various forms in later sections here. Note that this paper does not get into the algorithmic approaches used in different encryption approaches (like to-CBC or not-to-CBC) - the aim here is to help choose the right approach (and if choosing encryption, the right algorithm.) If you’d like to further nerd out on how the encryption itself works, drop us a note at [email protected].
Encryption has the advantage of being secure and flexible, but has the distinct disadvantage of requiring overhead of key management (more on this later, too.)
Why Choosing is Important
Now that we’ve got some definitions out of the way, the question at hand is “why is choosing a data protection approach important?” Or better yet, why can’t you just pick one arbitrarily and be on your way, or at least pick the easiest one to implement. They’re all protecting data after all, right? Unfortunately, no.
The choice of what to use between masking, tokenizing, hashing, or encrypting is (and should be) driven by:
- Your security requirements (how important the thing is that you’re protecting)
- Your appetite for technical complexity
- Your usage of the data that you’re protecting
Each form of protection we’ve covered has its own benefits and pitfalls, but if we assume that you want maximum security and that most systems (self-built and vendor-provided) can provide each option without heroics, we believe the biggest factor is your intended use of the data. After all, what good is the data if you can’t use it after you’ve protected it?
Here’s a bit of a cheat-sheet, which is not intended to be exhaustive, but may help you come up with some of the things that are important to your data so you can make the best choice.
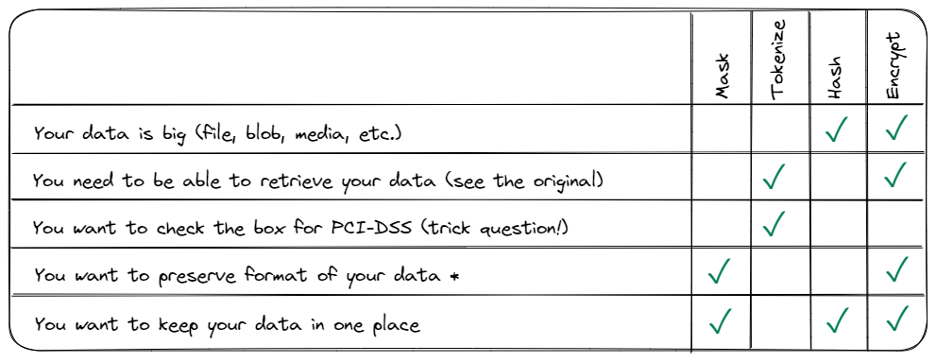
*Encryption using a format-preserving algorithm will allow for structural similarity between original text and ciphertext
Why We Chose Encryption
With the options available for protecting data, why did we choose to focus on encryption (and read between the lines - why do we largely think encryption is the right choice for you?)
The short answer is that we feel encryption is the only option that maximizes security while not losing flexibility and data ownership. Admittedly, encryption can be the most complex option, especially when considering key management. We focused the Ubiq solution on eliminating that barrier and making encryption simple and key management simple so that encryption becomes an available solution to everyone.
Encryption vs. Data Masking
Data masking has the disadvantage of being non-reversible (see note above on this assumption), which means that either:
- Masking is applied only at a visual layer, but the data itself is still stored in its full form, which leaves the data largely unprotected and doesn’t help close any of the storage-layer security gaps
- Masked data needs to be stored AND the original data needs to be stored, which adds significant complexity (like storing your own tokenized version) and also leaves the original data in need of a second protection solution
Encryption doesn’t suffer from either of these disadvantages - it by nature is reversible (decrypting) and can be stored in place because of that.
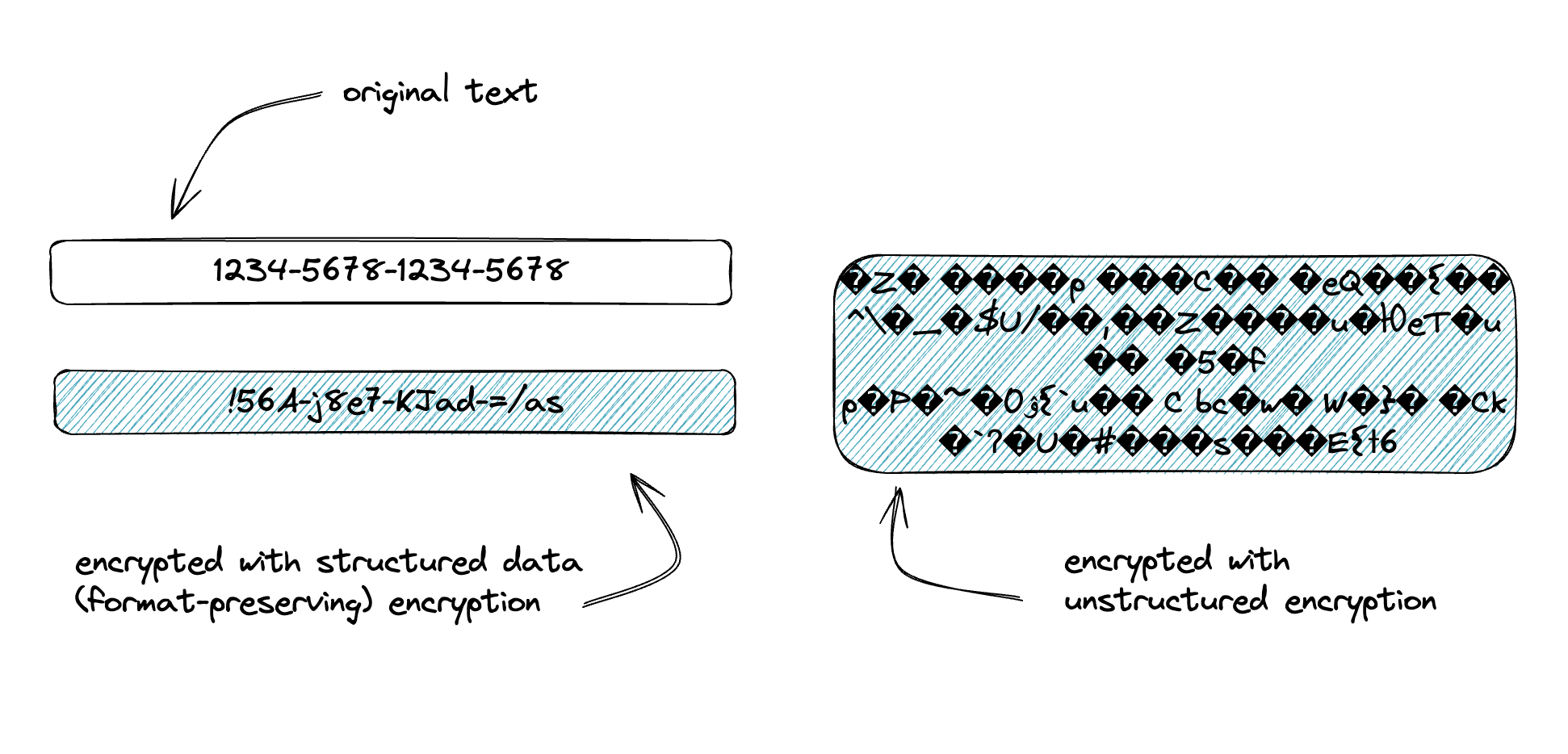
Data masking has the benefit of preserving the format of the original data so that it is recognizable, either by humans or software. With the use of a format-preserving encryption (like the NIST FFx algorithms), encryption can do the same. While format-preserving encryption won’t use the same character as the “mask,” it will preserve length and a character set that you define. “Partial” masking (i.e. masking all but the last 4 of a credit card number) can also be achieved with format-preserving encryption.
Encryption vs. Tokenization
Tokenization became popular to solve PCI-DSS needs without every ecommerce merchant needing to meet the security requirements for storing their own credit card information. It has become the de-facto solution for payment processors, but its purpose is to shift the security responsibility from the average website owner to the payment processor.
Ironically, those same payment processors must use encryption to protect the credit card data. Tokenization is not a “security” technique so much as a “shift-the-burden” technique. The cost of doing so is high, and generally impractical for any use-case that solely-focused on checking the PCI compliance box:
- Tokenization gives your data to someone else and you trust them to protect it (scary)
- In some larger organizations, tokenizing is used internally (the data is owned/stored by a different team), which also adds complexity of building and maintaining a tokenization service and still need to manage encryption of the original data
- Tokenization data doesn’t represent the real data at all, so it can’t be used for masking, testing, or any scenario where format/structurally-similar data is needed
Encryption (typically the format-preserving kind) has none of the disadvantages of tokenization - you own your data, your ciphertext can be used where masked data is desired, and nobody needs to store another copy of the data or maintain a large tokenization platform.
The barrier to using encryption (its disadvantage) is the complexity of implementation and key management (more on that later.)
Encryption vs. Hashing
Hashing is similar to encryption in that both are cryptographic approaches, using math to transform text. Hashing is a very useful tool in software development to turn data into a fixed-length representation with unlikely collisions. Hash tables or hashes as signing techniques are and will continue to be purposes well-served by hashes. It’s also the defact standard for password protection.
Hashing as a data protection technique, however, is up for debate. Hashing became popular for storing passwords so that as a user entered their password while logging in, it could be hashed and then the two hashes would be compared to determine if the user had entered the correct password. Only the hash would ever be stored. Unfortunately, SHA-1 was not as secure as people thought (just like 56-bit DES for encryption), and while mathematically the hash is not reversible, it is still breakable.
The main disadvantage of hashing with respect to data protection use-cases is that the hash itself is not representative of the original text. This isn’t so important if it is being used for validating passwords, but it is important when protecting other user data like credit cards, SSNs, etc.
Encryption Implementation Complexity
The main disadvantage of using encryption is typically the complexity that comes along with it. Decisions about algorithms, the inevitable deprecation of those algorithms, and securely storing and managing keys and key-to-data association can make implementing encryption complex and costly. Although encryption offers superior protection and usability in most cases, the additional work can offset that and make the decision of what technique to use less clear.
Our goal at Ubiq was to pretty much eliminate this complexity burden so that it isn’t a factor in choosing the best data protection technique for your data. Some of the approaches we take may be concepts that you can borrow if a vendor-based solution isn’t right for your data, so in the interest of transparency, our approach to algorithm and key complexity are outlined below.
Encryption Algorithm Choice & Key Management
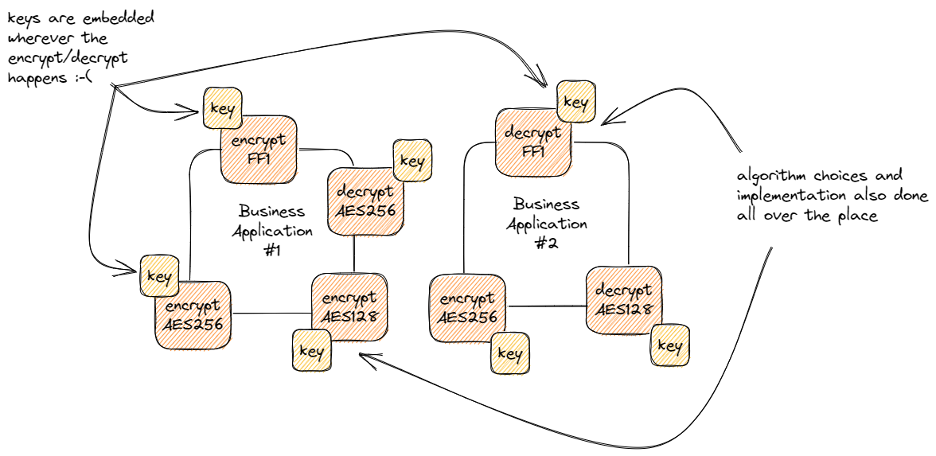
Typically, applications implement encryption in a way that the choice and technical details (i.e. code) for doing the encrypt/decrypt is distributed to all of the applications or places inside those applications where it is needed. This means that encryption is implemented in applications in each of the places where data needs to be encrypted implementing encryption. Whenever those things change, there’s a huge amount of work needed - like updating from AES-128 to AES-256 or rotating the key used in each place. Smart system design and automation can help with some of this - abstracting the algorithm choice, building the key into your CI/CD pipeline instead of the code, etc. Those things will help, but they directly trade off flexibility for maintainability - what if you want individual keys in different parts of the app or what if you don’t have an implementation for that quantum-resilient encryption algorithm yet?
Our approach at Ubiq is to abstract all of these things. In our case, that’s to a SaaS application for configuration (key management, algorithm choice, etc.) and to an SDK for implementation (AES-256, FF1-3, etc.) This, in our opinion, provides the best of all worlds:
- Flexibility of key management and secure storage
- Flexibility of algorithm choice
- Zero effort to associate keys to data
- Minimal effort to update implementation logic
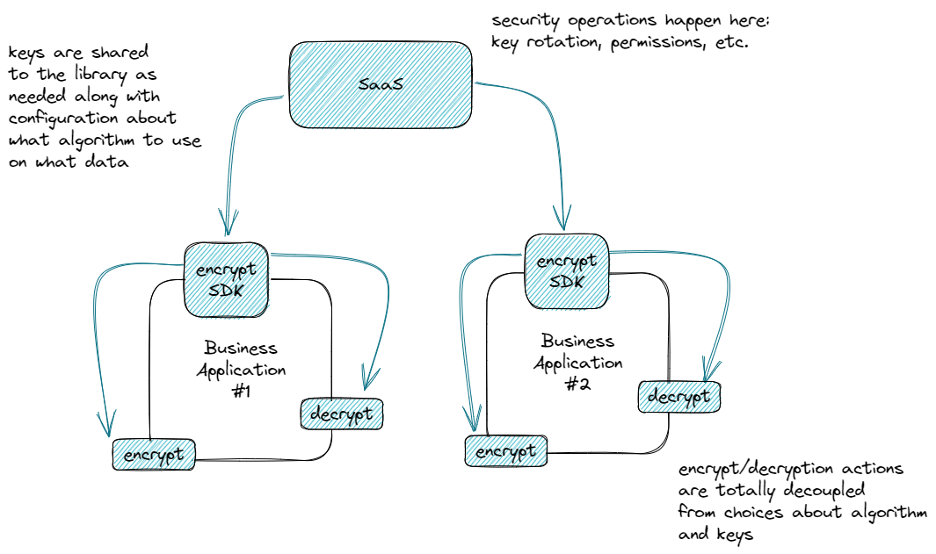
There is a little magic in our encryption implementations (more later on that) that allows the data itself to be portable, meaning that you don’t have to track what key was used to encrypt what data, the data itself knows that all by itself. By decoupling the keys and algorithm from the encrypt/decrypt operations, the implementation effort goes to near-zero and the impact of changing those choices later follows suit.
- No impact if keys change
- No impact if algorithm selection changes
- Only one place to update (pull a new version of the SDK) when a new algorithm is added
Encryption Types
We’ve termed structured encryption is a format-preserving, key-embedded encryption that is widely used when encrypting data that has length limitations, character/encoding limitations, or needs to retain the format/structure of the source data. Most of the time the data is stored in traditional relational databases and is small (under 1000 characters.) Unstructured encryption leverages AES encryption with embedded metadata and is used for everything else where format is irrelevant - blobs, files, media, streams. In our solution, we further associate these encryption types to “datasets,” allowing them to be mixed-and matched to your heart’s content. That’s not the topic of this paper, but for more reading, please see our Concepts document.
As with choosing the right data protection technique, your use-case should drive the type of encryption you ultimately choose. Key factors include whether you need to preserve format, the size of your data, if you have a specific need for key uniqueness, and performance.
We’ve got another cheat-sheet for this:

*Deterministic vs. random encryption can be done outside of this “default” behavior, but our approach to structured (format-preserving) encryption embeds keys to alleviate key management complexity. If using randomized, structured (format-preserving) encryption, the data must keep track of its own seed/initialization-vector, which adds significant complexity. Unstructured encryption does this automatically by default.
Structured (Format-Preserving) Encryption
Generally-speaking, if you’re encrypting data that lives in a column in a traditional RDBMS, you’ll want to use structured encryption. Databases are picky about column length and encoding/character sets and data in a database is often destined to be read by a human or software and structured encryption gives you some amount of readability.
Structured encryption also has the same benefits that you get from data masking - you can use the data for testing, display, or other human- or machine-readable use-cases because it looks like the source data. A SSN encrypted with format-preserving encryption will still look and feel like an SSN. Using some simple implementation techniques, you can turn this into “partial” encryption (i.e. leaving the last 4 digits unencrypted). Structured encryption is also deterministic, which lends itself to limited searchability and, when used with partial encryption, can overcome some hurdles of database orderability (more on that and the current-state of searchable - a la homomorphic - encryption in a different paper.)
With all of its benefits, structured encryption (at least in the implementation we’ve chosen at Ubiq, which embeds keys) has a finite number of different keys that can be used. You can remove that limit by managing your own data-to-key association, but then you’re adding back in a significant amount of complexity.
Unstructured Encryption
Unstructured encryption is used everywhere that format preservation is not needed ***
*** Except where it doesn’t make sense.
The general rules-of-thumb is that unstructured encryption is:
- The best option for anything large (files, blobs, etc.)
- The only option for streams
- Randomized (non-deterministic) and uses unique keys by default, so is arguably more secure
- Suitable where the size of ciphertext is not important (it will be larger than the source text, especially when using Ubiq because we embed 1-2k of metadata)
A Note About Ubiq Key Caching & Performance
One of the big considerations in implementation - not so much picking which encryption to use, but deciding how to use it - is performance. The performance impact of encryption is very dependent on the implementation and even more dependent on how keys and algorithm configurations are managed. The compute effort to do the actual encryption tends to have the smallest performance impact, so we have some basic guidelines for our own implementations. These are definitely useful for anyone using our SDKs, but may also be helpful if you’re going out on your own.
Assumptions about encrypt types and their use of keys:
- By default, unstructured encryption gets a new key every time an encrypt is done
- Unstructured ciphertext has metadata about the key being used and since they are unique (see #1), every time unstructured ciphertext is decrypted, the key that is needed for it must be fetched
- Structured data has limited key rotations due to key embedding, and so by default a structured data key will be re-used (and cached) for the duration the SDK is alive
Assumptions about performance of operations:
- Fetching of keys is a much more expensive (performance-wise) operation than doing encryption because for us, it means an API call over the internet (200-400 ms depending on where you are)
- Encrypt operations are sub-millisecond for structured data of reasonable size and 5-50ms per 10mb of data for unstructured data depending on the chipset
As you can see from those stats, minimizing key retrievals is critical to good performance design. In our SDKs, we help with automatic caching and configuration options for re-using unstructured keys, but every application needs to consider this in their design.
Summary
We’ve meandered around encryption definitions, Ubiq capabilities, and how to choose the right data protection approach. If you skipped all of that and want the quick version, here’s the highlights:
- Data protection using masking, tokenization, and hashing is inferior to using encryption as long as you can get key and algorithm management done right
- Structured (format-preserving) and Unstructured encryption serve different use-cases, but draw a basic delineation on use between small, human-readable ciphertext and files/blobs/streams
- Design of key caching is critical to performance
- For encryption to be practical and lightweight, key management needs to be abstracted from the encryption implementation (and same for algorithm changes/selection)
- Ubiq does some magic to embed keys within the ciphertext of data to make this possible with our SaaS solution and SDK
Updated over 1 year ago