

How to Encrypt Structured Data
Once you’ve made the choice to use structured data encryption (also known as "format-preserving encryption" or "FPE"), you might get curious about how it actually works. This paper is intended to provide a guide on using structured data encryption in the Ubiq SDK and arm you with some working knowledge about how structured data encryption operates.
If you haven’t decided what type of data protection is right for you yet, start at this white paper for help in choosing the right data protection for your needs, and then come back once you’ve decided that structured data encryption is what you need.
Encryption - Structured vs. Unstructured Data Encryption
As a quick refresher, encryption (to us at Ubiq) gets defined as a mathematical/cryptographic process that applies a “key” to a sensitive text to change the characters in a way that is reversible.
There are many different types of encryption, from the cracker-jack-box decoder ring that turns “A” into 1, “B” into 2, etc. to common algorithms like AES-256 and uncommon algorithms that maintain format and character preservation.
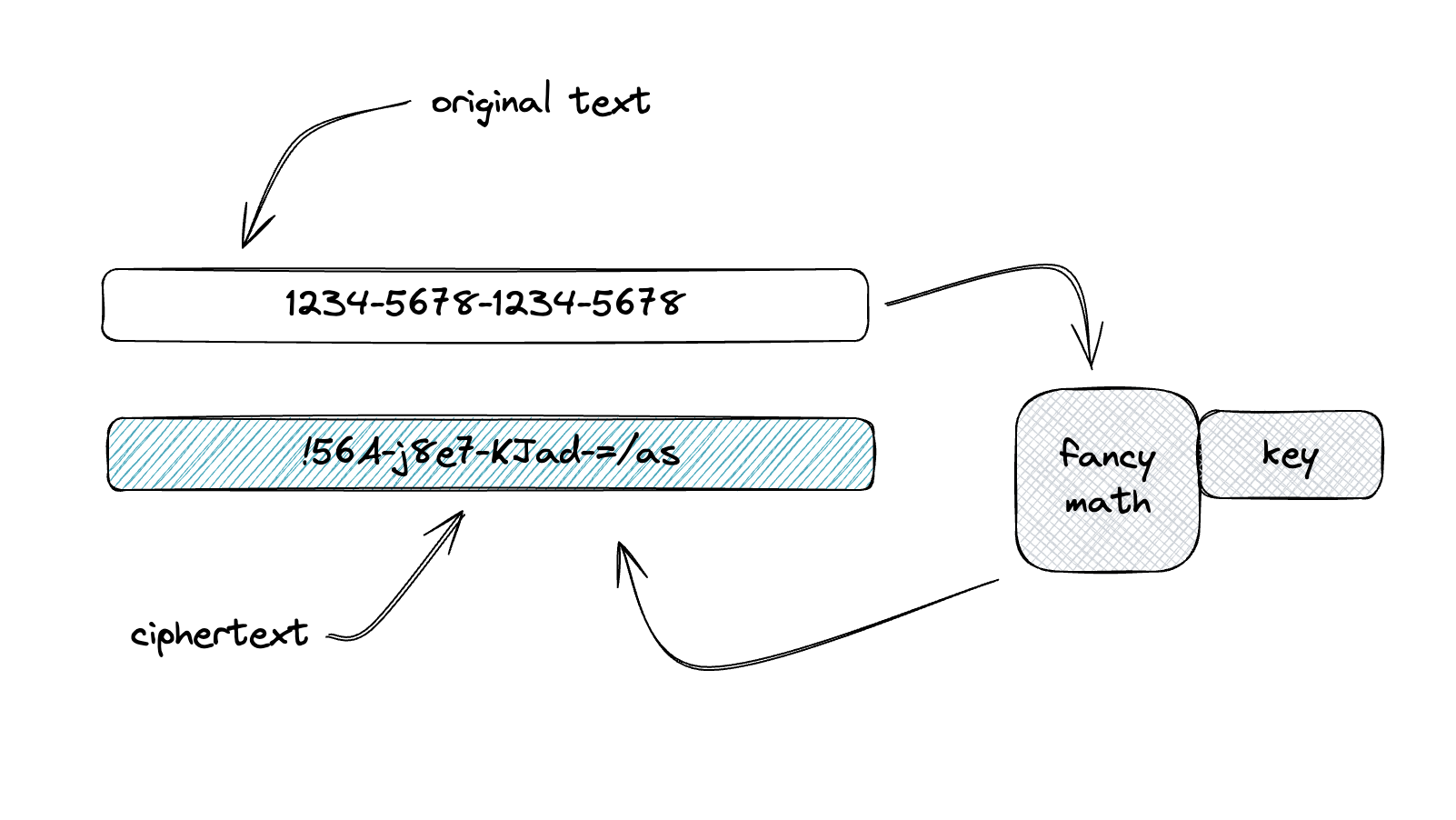
We tend to have strong opinions about encryption, but we did manage to settle on two common terms that make it easy to navigate. If you’re reading this paper, you may have already decided that you need structured data/format-preserving encryption. If that’s you, feel free to skim this next part, but if you’re still deciding what type is right for you, this will guide you:
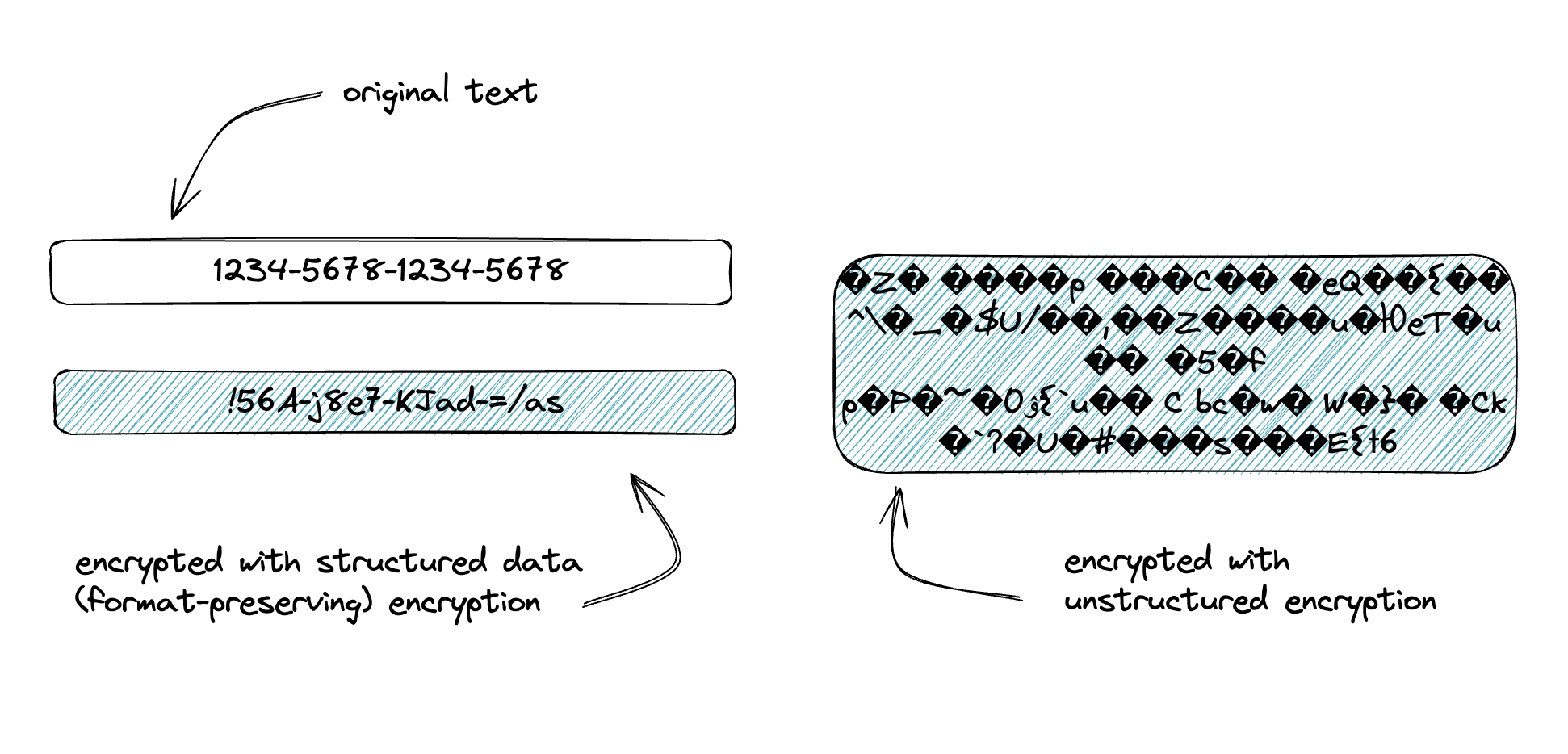
We’ve termed structured data encryption as a a format-preserving, key-embedded encryption that is widely used when encrypting data that has length limitations, character/encoding limitations, or needs to retain the format/structure of the source data. Most of the time the data is stored in traditional relational databases and is small (under 1000 characters.) Unstructured encryption leverages AES encryption with embedded metadata and is used for everything else where format is irrelevant - blobs, files, media, streams. In our solution, we further associate these encryption types to “datasets,” allowing them to be mixed-and matched to your heart’s content. That’s not the topic of this paper, but for more reading, please see our white paper on data protection techniques.
As with choosing the right data protection technique, your use-case should drive the type of encryption you ultimately choose. Key factors include whether you need to preserve format, the size of your data, if you have a specific need for key uniqueness, and performance.

*Deterministic vs. random encryption can be done outside of this “default” behavior, but our approach to structured data (format-preserving) encryption embeds keys to alleviate key management complexity. If using randomized, structured data (format-preserving) encryption, the data must keep track of its own seed/initialization-vector, which adds significant complexity. Unstructured data encryption does this automatically by default.
Structured Data Encryption (Format-Preserving-Encryption)
Generally-speaking, if you’re encrypting data that lives in a column in a traditional RDBMS, you’ll want to use structured data encryption. Databases are picky about column length and encoding/character sets and data in a database is often destined to be read by a human or software and structured data encryption gives you some amount of readability.
Structured data encryption can be used as test data, masking, or other human- or machine-readable use-cases because it looks like the source data. A SSN encrypted with format-preserving encryption will still look and feel like an SSN. Using some simple implementation techniques, you can turn this into “partial” encryption (i.e. leaving the last 4 digits unencrypted). Structured data encryption is also deterministic, which lends itself to limited searchability and, when used with partial encryption, can overcome some hurdles of database orderability (more on that and the current-state of searchable - a la homomorphic - encryption in a different paper.)
With all of its benefits, structured encryption (at least in the implementation we’ve chosen at Ubiq, which embeds keys) has a finite number of different keys that can be used. You can remove that limit by managing your own data-to-key association, but then you’re adding back in a significant amount of complexity, which most people would rather avoid.
Unstructured Data Encryption
Unstructured data encryption is used everywhere else.
The general rules-of-thumb is that unstructured data encryption is:
- The best option for anything large (files, blobs, etc.)
- The only option for streams
- Randomized (non-deterministic) and uses unique keys by default, so is arguably more secure
- Suitable where the size of ciphertext is not important (it will be larger than the source text, especially when using Ubiq because we embed 1-2k of metadata)
What is Ubiq’s Structured Data Encryption
So what actually is structured data encryption, and why do I keep parenthetically referring to it as “format-preserving encryption”? Our industry has not yet standardized on a set of terms for all of the different types of encryption. Some are becoming a bit more widely-accepted, such as “homomorphic” (oh but there’s still a ton of ambiguity between fully-homomorphic vs. not or “searchable encryption”) or “quantum resilient.” But anytime the term needs quotes or parentheses probably means it’s not clear enough on its own and needs some further explanation. Enter the Ubiq-coined terms of structured and unstructured data encryption that we just discussed.
Ubiq’s structured data encryption is based on the NIST-adopted algorithm for format-preserving encryption you can find here and the subsequent algorithmic guides. We are using the FF1 implementation (FF3 was deemed insecure) and have added our own technique for key-embedding as well as added enforcement in our structured configuration to ensure a minimum number of key rotations.

Performance Considerations of Structured Data Encryption
One of the big considerations in implementation - not so much picking which encryption to use, but deciding how to use it - is performance. The performance impact of encryption is very dependent on the implementation and even more dependent on how keys and algorithm configurations are managed. The compute effort to do the actual encryption tends to have the smallest performance impact, but when and where the Ubiq SDK fetches data keys from our SaaS service can make or break SLAs. We have some basic guidelines to help you make good design choices when implementing structured data encryption.
Default behavior:
- Structured data has limited key rotations due to key embedding, and so by default a structured data key will be re-used (and cached) for the duration the SDK is alive.
- Fetching of keys is a much more expensive (performance-wise) operation than doing encryption because for us, it means an API call over the internet (200-400 ms depending on where in the world the call is originated from).
- Encrypt operations are sub-millisecond for structured data of reasonable size and 5-50ms per 10mb of data for unstructured data depending on the chipset.
Good ideas:
- Implement the SDK instantiation in a global / singleton / once-per-thread scope so that the authentication calls to our SaaS backend only happen once.
- Data keys are fetched every time you encrypt with a new structured dataset or every time you decrypt with one and the key that’s needed is not in cache.
- Use the non-static implementation calls of the SDK (the static calls have already been deprecated in some languages) to take advantage of key caching in the top-level SDK object.
- Optionally, warm up your key cache by doing a synthetic encrypt or decrypt of data for each dataset you’ll be using to get those keys into the cache.
Implementation Design Considerations
The scope of this paper doesn’t include use-case examples on where to implement the Ubiq SDK based on your application type - we’ve got lots of those examples in our use cases - but there are some general good ideas to make your implementation and maintenance life easier that we recommend.
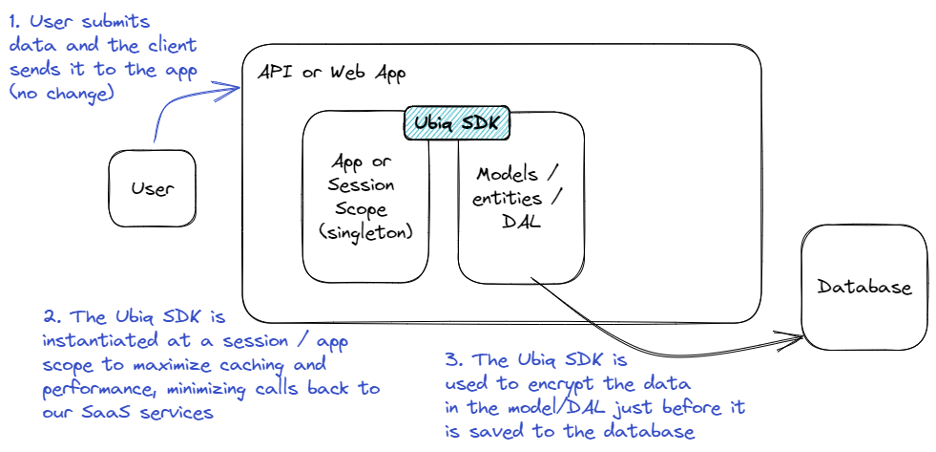
Ubiq SDK is most typically added in the model/DAL layer so that it can be invoked right before data is stored and right after data is retrieved. This reduces the amount of impact to other areas of the application because as the data is used elsewhere, it is (in memory) in its plaintext form.
A typical application flow for a web application with Ubiq integrated might look like this:
Setting Up to do Structured Data Encryption/Decryption
I assume (as author of this fine article), that my audience is an implementer - a software developer or security engineer, that either due to their own security-mindedness or because someone told them to, needs to add encryption to some application.
In many cases (especially bigger companies), software is a different org than the security org and they may or may not play nice together. In smaller places, everybody does everything. If you’re part of the former, then you may not ever see the Ubiq UI (the SaaS app) and someone just handed you a set of API keys and dataset names.
For everyone else, there is some initial configuration that happens in the Ubiq app to create datasets, configure their encryption rules, and provision access via API keys. Lots of other security administration can be done there, too, like rotating or organizing cryptographic primary keys, data keys, managing security logs, and things of that ilk. You can read all about it in our documentation here and through all of the “Ubiq Guide” sections. You can also sign up for a free trial account and experience it all for yourself.
At a minimum, you’ll need to do a few things before you can use the Ubiq SDK to do a structured encrypt or decrypt:
- Sign up for an account.
- Create a Structured Data Set.
- Copy the API keys that are given to you ad the end of #2 (you’ll use them in the SDK)
- Copy the dataset name that you just created (you’ll reference that in the SDK too)
That’s it - not a lot, but if you recall from our overview paper, the SDK works hand-in-hand with the Ubiq SaaS backend to exchange keys and configuration info to make your encryption/decryption possible.
Performing a Structured Encrypt/Decrypt
Our public documentation provides examples for each of our SDKs. Look for the “Structured Data Encryption” section in any of the “Developer Client Libraries” links in the left nav, such as this one for .NET. The “bulk encryption” or “bulk decryption” sections will describe the usage noted above that leverages key caching. The “simple encryption” and “simple decryption” will not automatically provide any caching and should be used with caution.
Generally, each library uses the same naming and implementation pattern
here for our SDKs walks through examples for each language. The language will dictate the syntax and some of the conventions, like NodeJS which defaults to async calls like this:
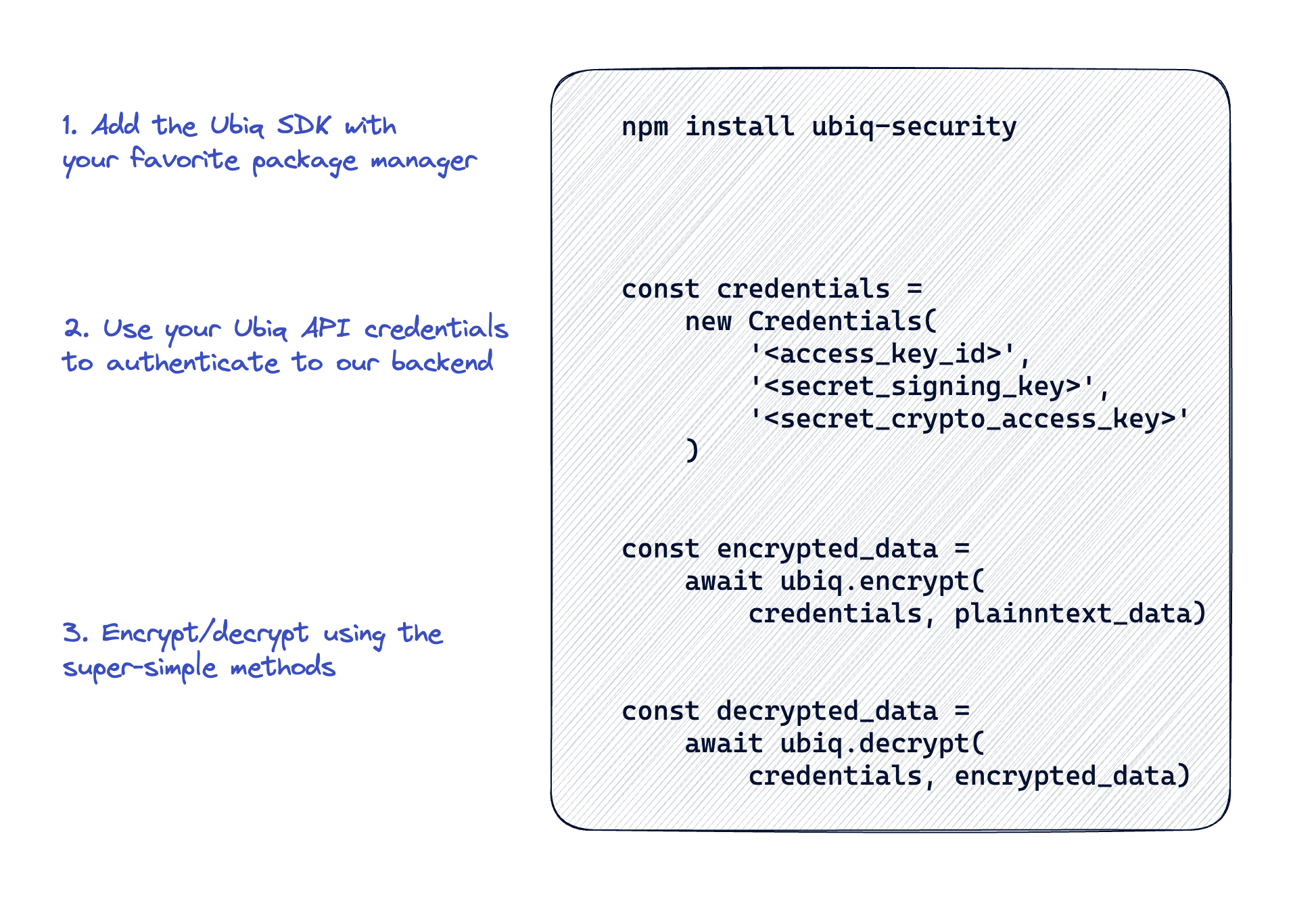
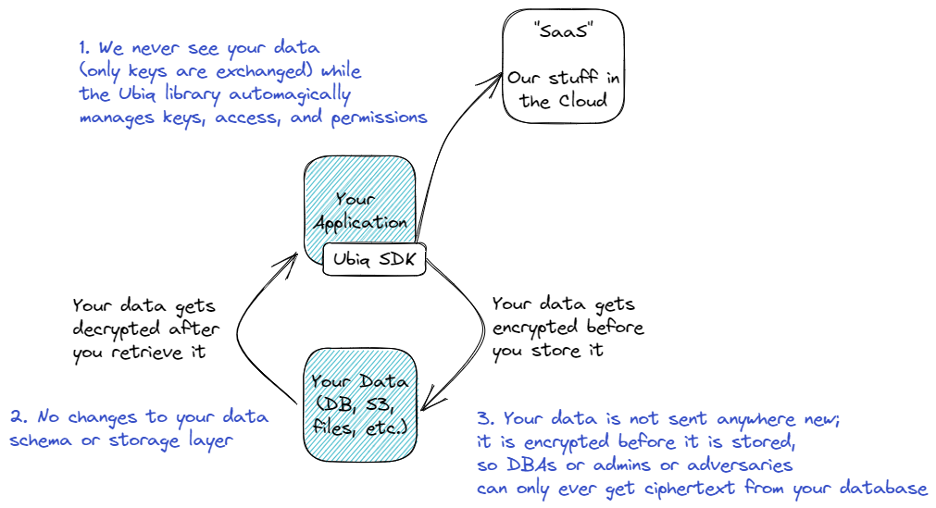
The implementation is intended to be simple and quick, with no expectation that you can implement an actual crypto algorithm. Even moreover, the implementation is abstracted from the choice of algorithm and keys so that if you need (or somebody in your security org decides) to change them later, it can entirely be done from our UI and doesn’t require code changes. The implementation itself has 3 parts as illustrated above:
- Include from your package manager (language-specific)
- Use a set of API keys issued from our SaaS backend to instantiate the Ubiq FPE object
- Use one of two simple methods - encrypt() or decrypt()
Summary
Assuming you landed here because you know you want to use structured data encryption to protect your data, this how to paper should have armed that decision with some implementation knowledge. If you haven’t decided yet, reading this white paper is a good place to start that compares structured and unstructured data encryption and the benefits of using structured data encryption over other data protection approaches like masking and tokenization.
Structured data encryption gives you the protection of a NIST-approved encryption algorithm with the benefits of format preservation, and when done using Ubiq’s SDK, the implementation is less than 10 lines of code and you don’t have to manage any keys. With some design consideration on where to implement the Ubiq library to best utilize key caching (like a singleton), you can follow the language-specific examples in our dev docs here [this link to library examples] to get up and running.
Updated 8 months ago