

How to Partially Encrypt (Mask) Data While Preserving Format
Using structured encryption, which preserves format, has a ton of different use-cases. One common use is to replace, or implement, an alternative to traditional masking. This brief paper will walk through why you might want to do that, and once you’ve decided that it fits your use-case, it’ll guide you in the technical implementation of partial (or full) masking using structured encryption with Ubiq.
You can skip ahead and catch up on your own, but these other introductions will provide context:
- For basic Ubiq concepts click here.
- For deciding if structured data encryption is right for your use case click here.
- For a general walkthrough of how to use structured data encryption click here.
Data Masking Use-Case Examples
Data masking (full or partial) as a concept can be applied to service a lot of different use-cases; if you’re here, you might already know what you’re trying to solve with it. If you’re just exploring, though, these examples may help inspire some ideas where data masking (structured data encryption!) might be helpful to you:
Data Masking:
Consider a scenario where a healthcare organization needs to share a medical research dataset with external partners while protecting patient privacy. The dataset includes sensitive information such as patient names, social security numbers (SSNs), and medical diagnoses. To ensure privacy, the organization applies data masking to the dataset.
Original data:
Patient Name: John Doe
SSN: 123-45-6789
Diagnosis: Hypertension
Masked data:
Patient Name: Jane Smith
SSN: XXX-XX-XXXX
Diagnosis: Hypertension
In this example, the patient's name and SSN have been replaced with fictional values to protect the privacy of the individuals involved. The diagnosis field remains unaltered since it does not contain sensitive information. By applying data masking, the organization can share the dataset with external parties for research or analysis purposes while safeguarding patient confidentiality.
Partial Data Masking:
Let's consider an organization that operates a customer relationship management (CRM) system. They need to provide a test environment for software development and quality assurance (QA) teams while ensuring the protection of sensitive customer data. In this case, partial data masking is implemented.
Original data:
Customer Name: John Doe
Email: [email protected]
Phone Number: 555-123-4567
Credit Card Number: 1234-5678-9012-3456
Partially masked data:
Customer Name: John Doe
Email: [email protected]
Phone Number: 555-XXX-XXXX
Credit Card Number: XXXX-XXXX-XXXX-3456
In this example, the organization masks sensitive data such as the phone number and credit card number. The customer name and email address remain unaltered as they do not contain sensitive information. By applying partial data masking, the organization can provide realistic test data for development and QA purposes without exposing sensitive customer details that could potentially lead to data breaches or misuse.
Both data masking and partial data masking techniques help organizations protect sensitive information while ensuring data availability for various purposes. The specific approach and fields selected for masking depend on the privacy requirements, data sensitivity, and the intended use of the masked data.
Encryption vs. Data Masking
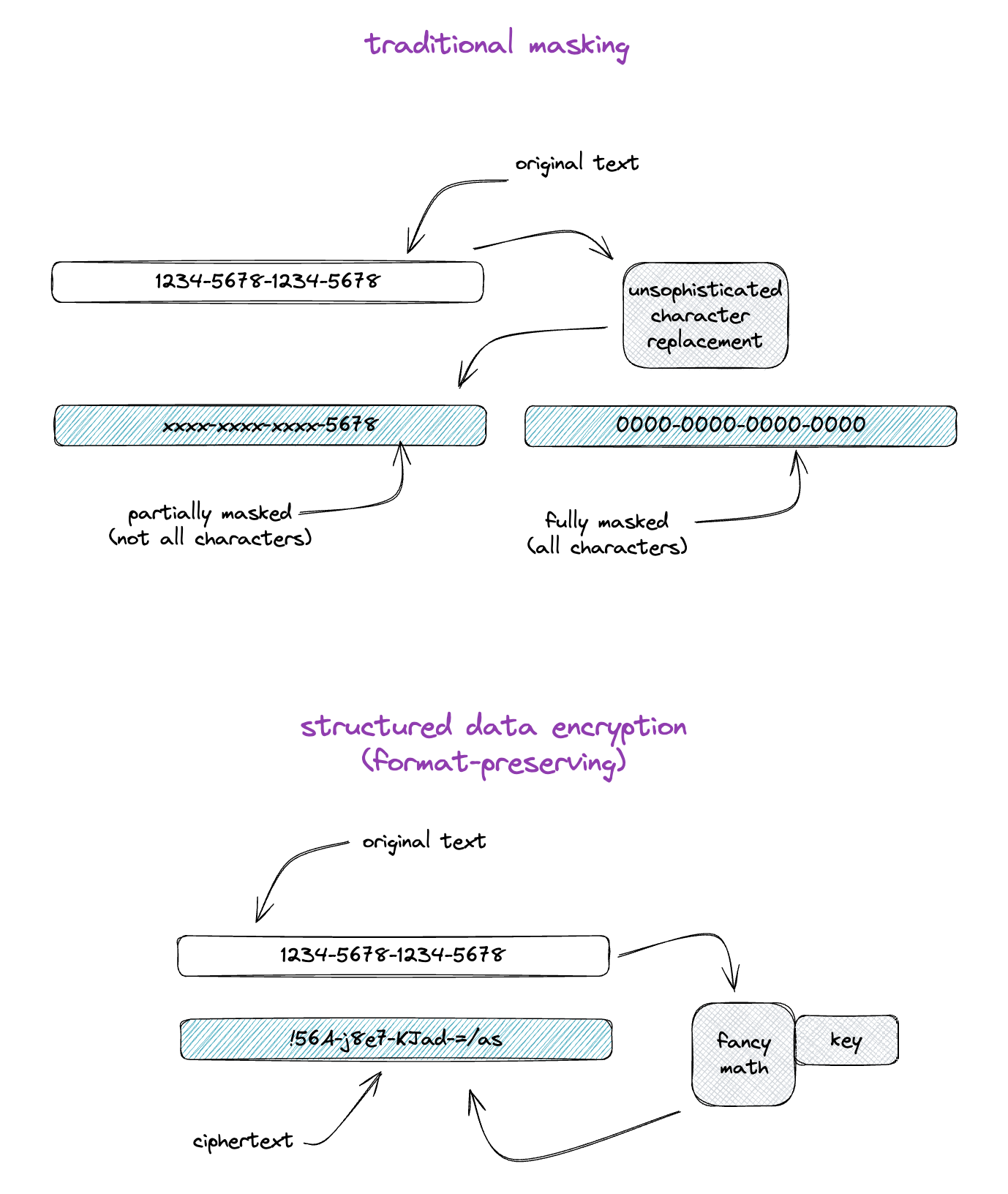
Data masking is a technique used to protect data by changing the characters in a piece of data so that it is no longer sensitive, but is recognizable in structure. The characters used in masking are arbitrary, but it is common to use a single character like an “x” or a dot or a zero. It is important to also note that masking in its traditional form is non-reversible, meaning that the original text cannot be retrieved from the masked text.
Data masking can be full, where all of the characters are changed (like when you type a password into a form on a website and it is replaced by dots), or it can be partial where only a subset of characters are changed (like when you see your bank account number on a statement and it only shows the last 4 digits.)
The advantage of masking is that it can be used “in-place,” meaning that the masked data structurally looks and feels like the original data, so an application or a human that’s seeing it doesn’t need to change when data goes from plaintext to masked text. This is advantageous when that data is stored in a database (with length or character restrictions), used for other logic in business processing, or needs to be readable.
Data masking has the disadvantage of being non-reversible, which means that either:
- Masking is applied only at a visual layer, but the data itself is still stored in its full form, which leaves the data largely unprotected and doesn’t help close any of the storage-layer security gaps
- Masked data needs to be stored AND the original data needs to be stored, which adds significant complexity (like storing your own tokenized version) and also leaves the original data in need of a second protection solution
Why Choose Encryption
Encryption doesn’t suffer from either of these disadvantages - it by nature is reversible (decrypting) and can be stored in place because of that.
Data masking preserves the format of the original data so that it is recognizable, either by humans or software. While format-preserving encryption won’t use the same character as the “mask,” it will preserve length and a character set that you define. Partial masking (i.e. masking all but the last 4 of a credit card number) can be achieved with a Ubiq Structured Dataset by configuring partial encryption rules, which are then automatically applied when encryption is done through a Ubiq SDK or Integration.
Encryption supports far more use-cases because the original data is retrievable. It provides cryptographically secure data protection, human- or logic-readable output (just like masking), but doesn’t force you to lose or duplicate the full content just to achieve your masking goals.
With flexible configuration options for Ubiq’s Structure Datasets, you can configure your encryption to leave some parts of a string unencrypted (like a way to leave the last 4 or the first digit of a credit card number as plain text). So instead of assuming (or hoping) that every application implements logic that properly parses, encrypts, concatenates, and stores data with the right parts encrypted… you can set a configuration once and every Ubiq Client Library will inherit and apply the encryption rules for that dataset.
Structured Data Encryption
Masking Concepts - The Old Way
The concept of partial masking applies equally as well to structured data encryption - the basic idea is that you want a piece of your content to remain unchanged while protecting the rest. When data is masked, this is almost always implemented manually with some software logic that says:
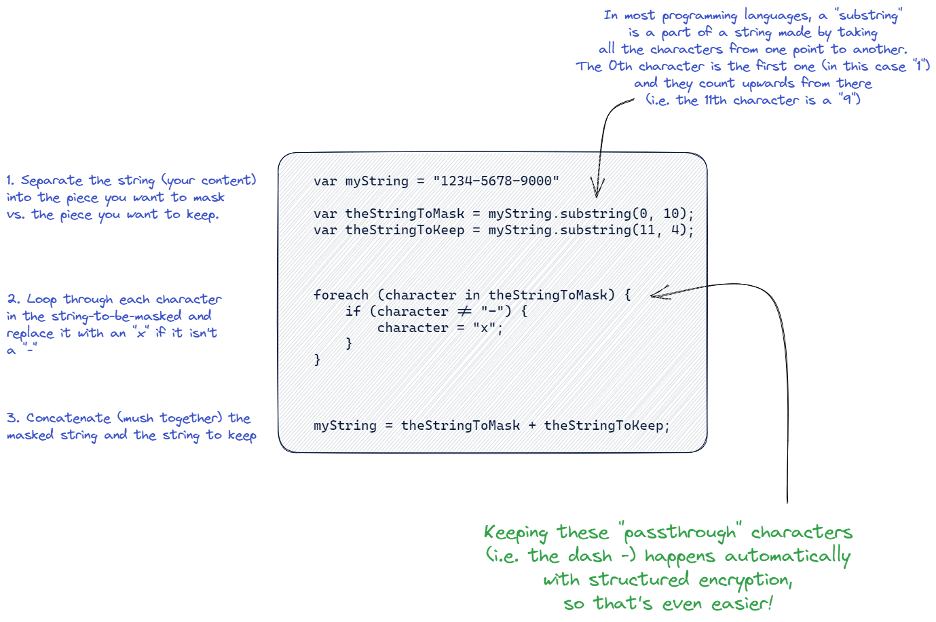
The steps are pretty straightforward, though in the defense of quality software teams out there, many may have abstracted this and/or implemented a general-purpose masking set of methods that simplify this or make it easier:
- Separate the string into the part you want to protect (replace with “x”s) and the part you don’t
- Do your replacement on the part you want to protect - see the note in the diagram that this can get annoying in masking logic because there is oftentimes a character or set of characters you want to keep (like the dash). Using structured datasets with Ubiq makes this happen automatically with structured data encryption, so you don’t have to worry about any of that.
- Combine the replaced and the pass-through strings together to get the whole thing again
And if you’re using encryption as your masking approach (which we hope you are), it might look like this:

- Separate the string into the part you want to protect the part you don’t
- Run encryption on the part you want to protect (that’s it!)
- Combine the results of the encryption and the part of the string you wanted to keep
This isn’t much easier, and although it’s not super complex for a dev to add, why do this by hand and hope everyone does it the same if you can instead let someone set policy and have it done for you without any code? Structured data encryption (see rant above on the lack of helper methods) is the same - but a little easier - than the masking concepts. Because passthrough characters are already handled automatically, you don’t have to worry about the replacement of those, and instead the 3 steps for masking turns into 3 (simpler) steps with encryption:
Ubiq Structured Dataset with Partial Encryption - The New Way
Doing the same thing with a Ubiq Structured Dataset is (literally) a point-and-click sort of activity. No code changes, no code to write at all. In fact, a security administrator, or policy writer, can configure the rules for what parts of a Social Security Number, Credit card number or email address should be encrypted vs. left in the clear and those rules will be automagically applied by the Ubiq library. Okay, maybe not so magically, but we’ll do the string exploding, encrypting, and concatenating for you so you don’t have to maintain that logic everywhere in your code.
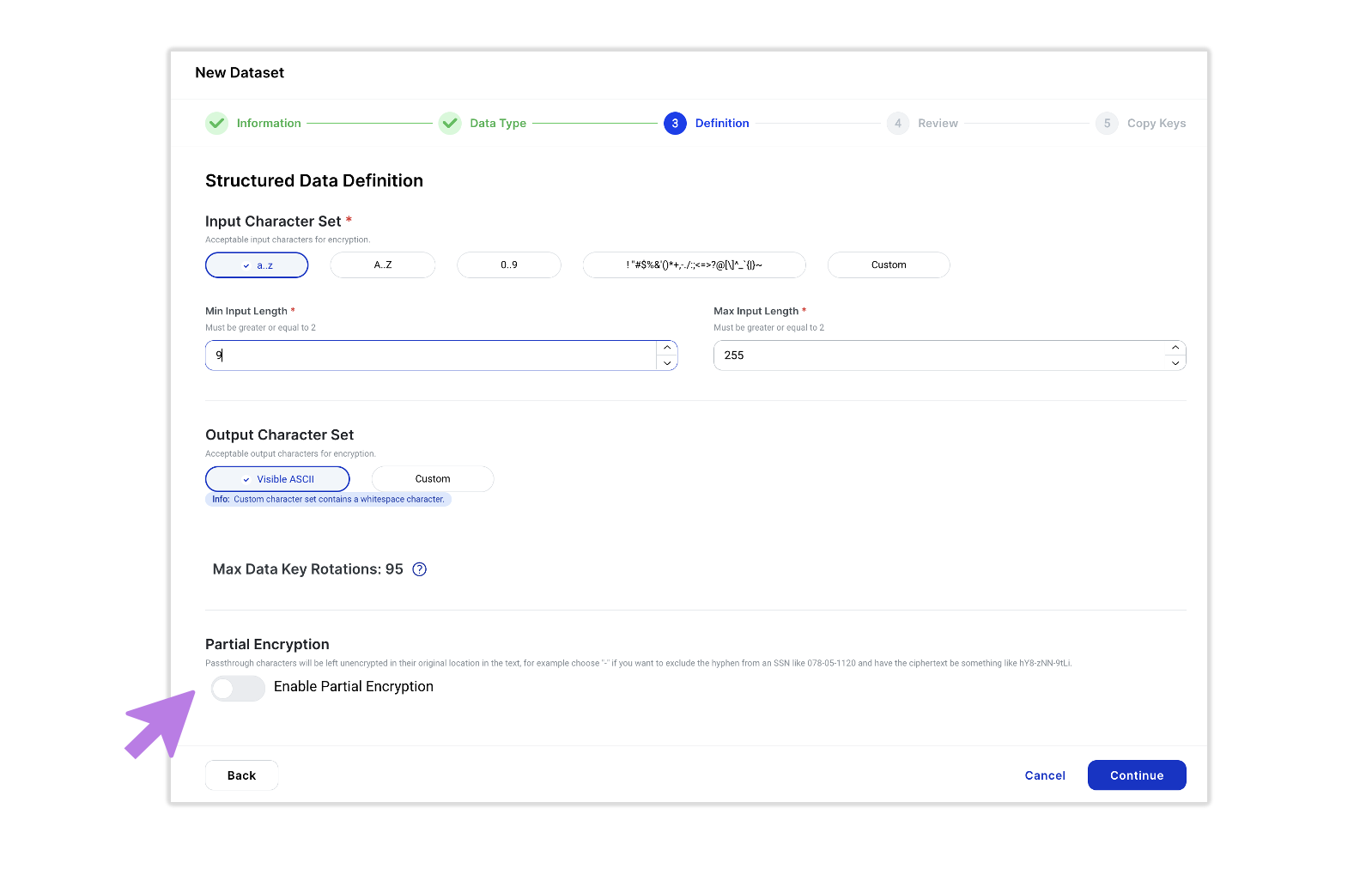
Partial encryption activation and no-code setup is enabled during the Ubiq Structured Dataset Definition step when creating a new Dataset:
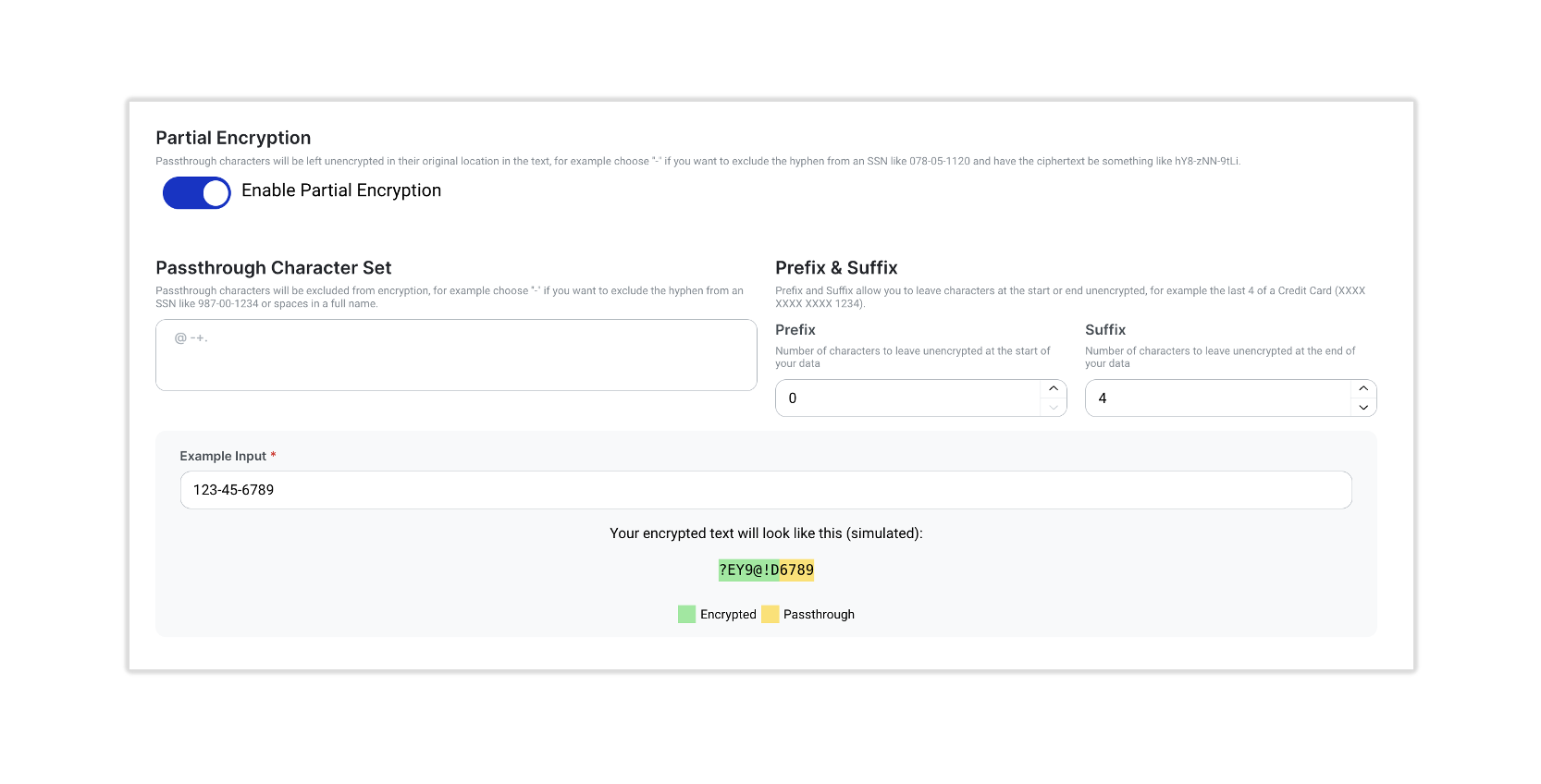
During the Structure Data Definition step, one simply enables the partial encryption option located at the bottom of the Structured Data Definition page, and then sets the passthrough characters and both prefix and suffix characters to leave unencrypted:
The following example illustrates setting up the masking of a Social Security Number leaving just the last 4 digits of the number in plaintext. Note that the user can test their rule settings using the Example Input Field and verifying the simulated output prior to continuing:
Summary
As a follow-on to the comparison of masking and structured data encryption in your decision-making process here, partial structured data encryption has a bunch of benefits when compared to traditional masking. As a simple configuration option when creating your dataset in Ubiq, this is a powerful way to achieve masking without any additional development work or risk. In the dataset setup wizard, simply:
- Start with a structured dataset
- Enable partial encryption rules
- Set a “starting” or “ending” number of characters to leave in the clear
- Check your rules in the handy “tester” box to make sure the cipher output is what you expect
- And you’re done! (you don’t need to have your developer do anything)
With that at your fingertips, partial masking via partial-structured-data-encryption can be a tool at your disposal to improve the options you have when protecting your data.
Updated over 1 year ago